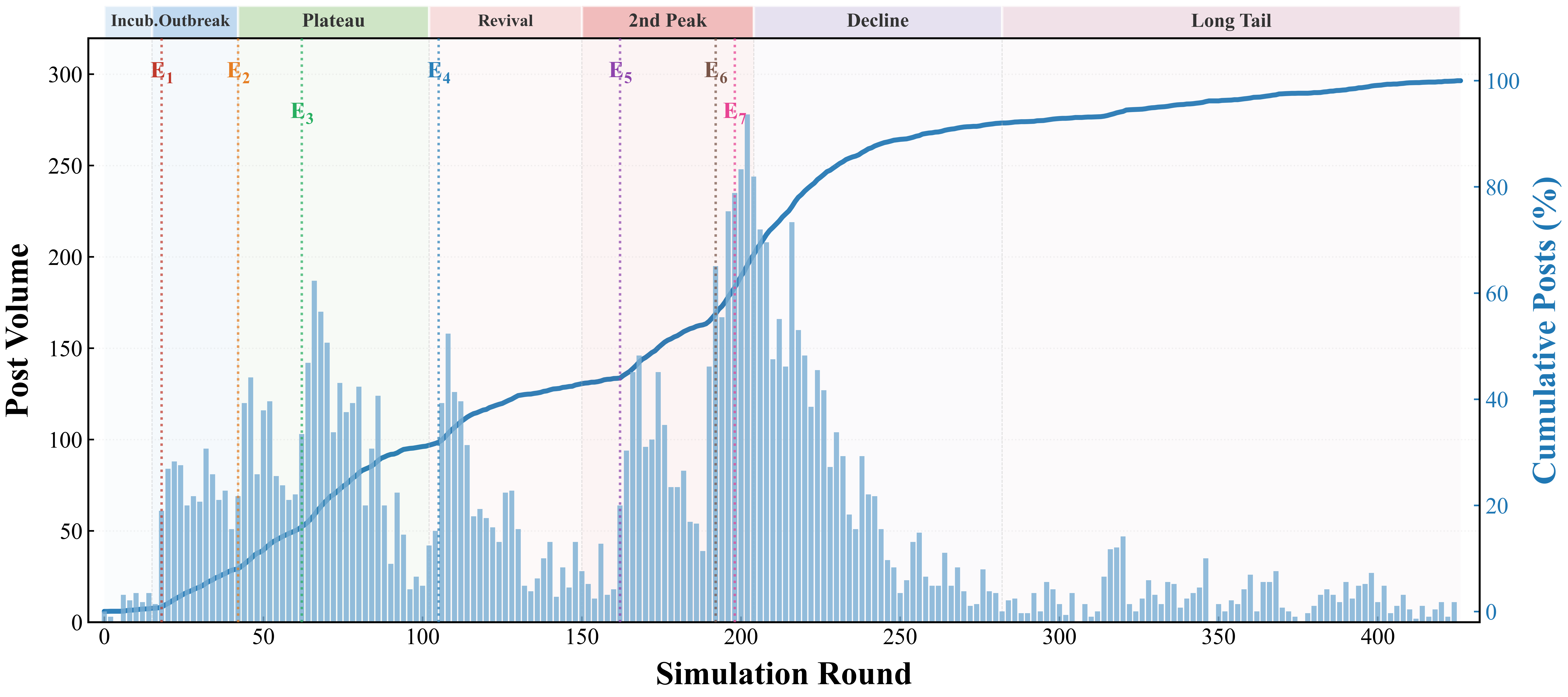
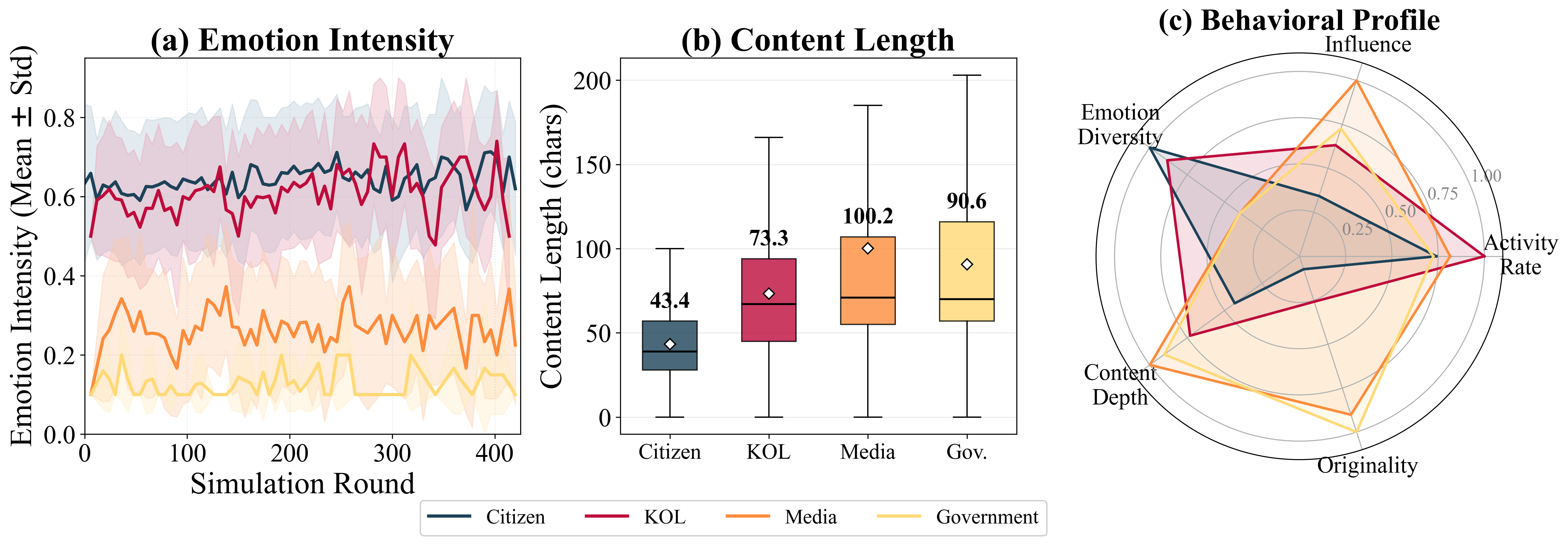
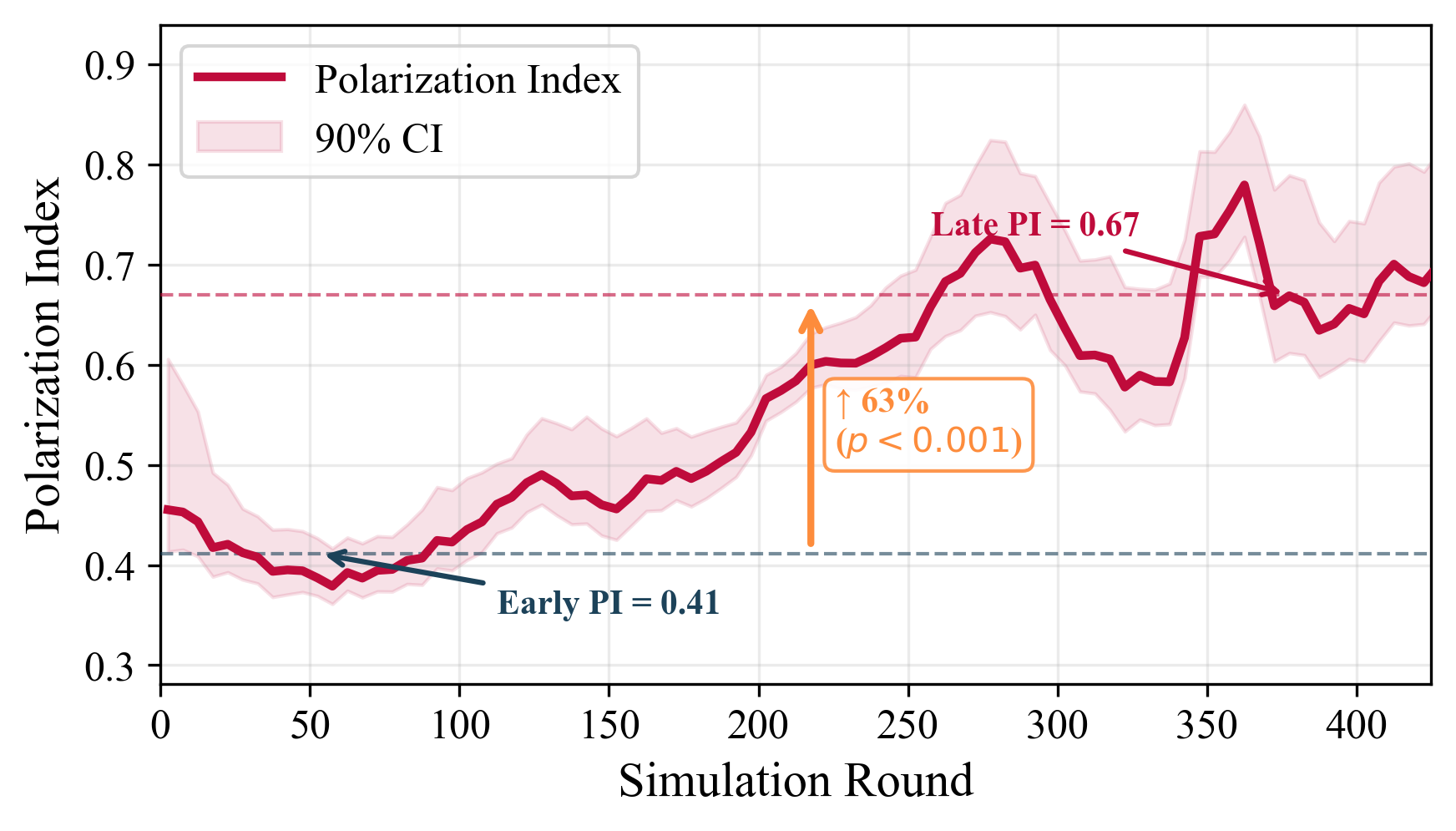
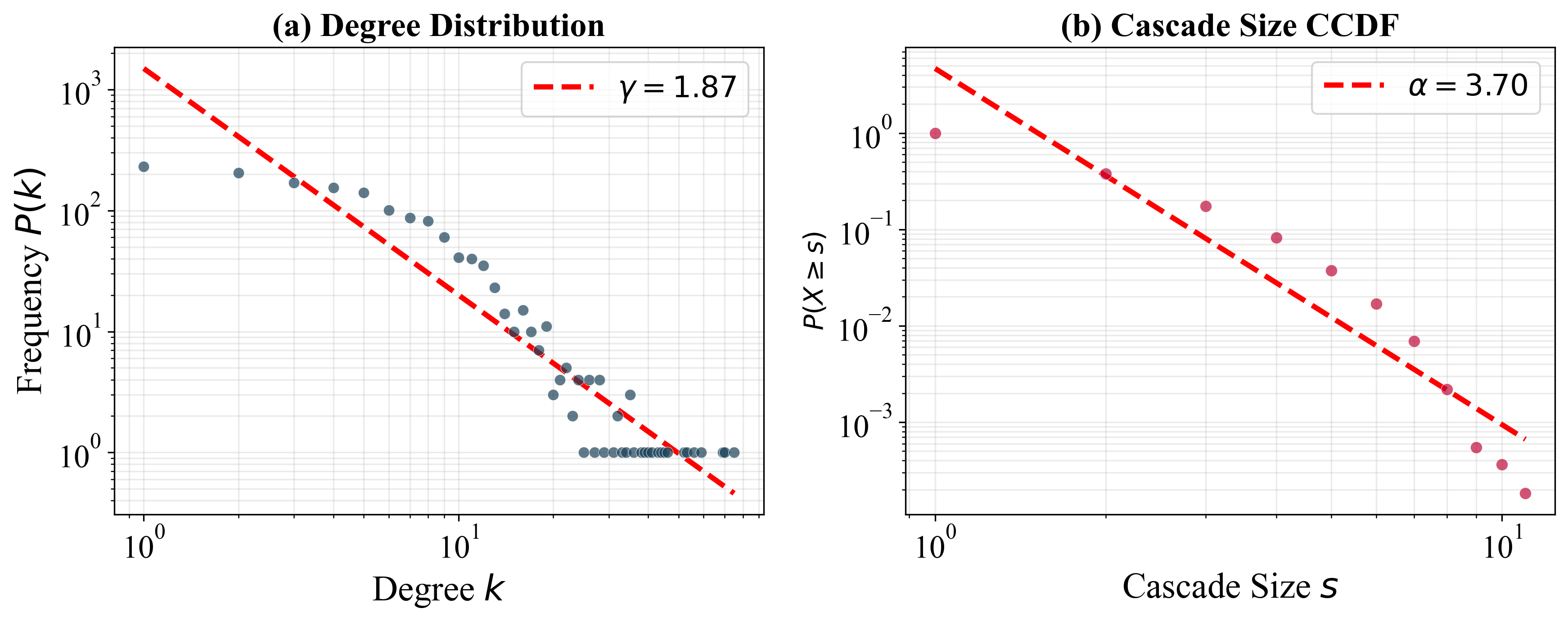
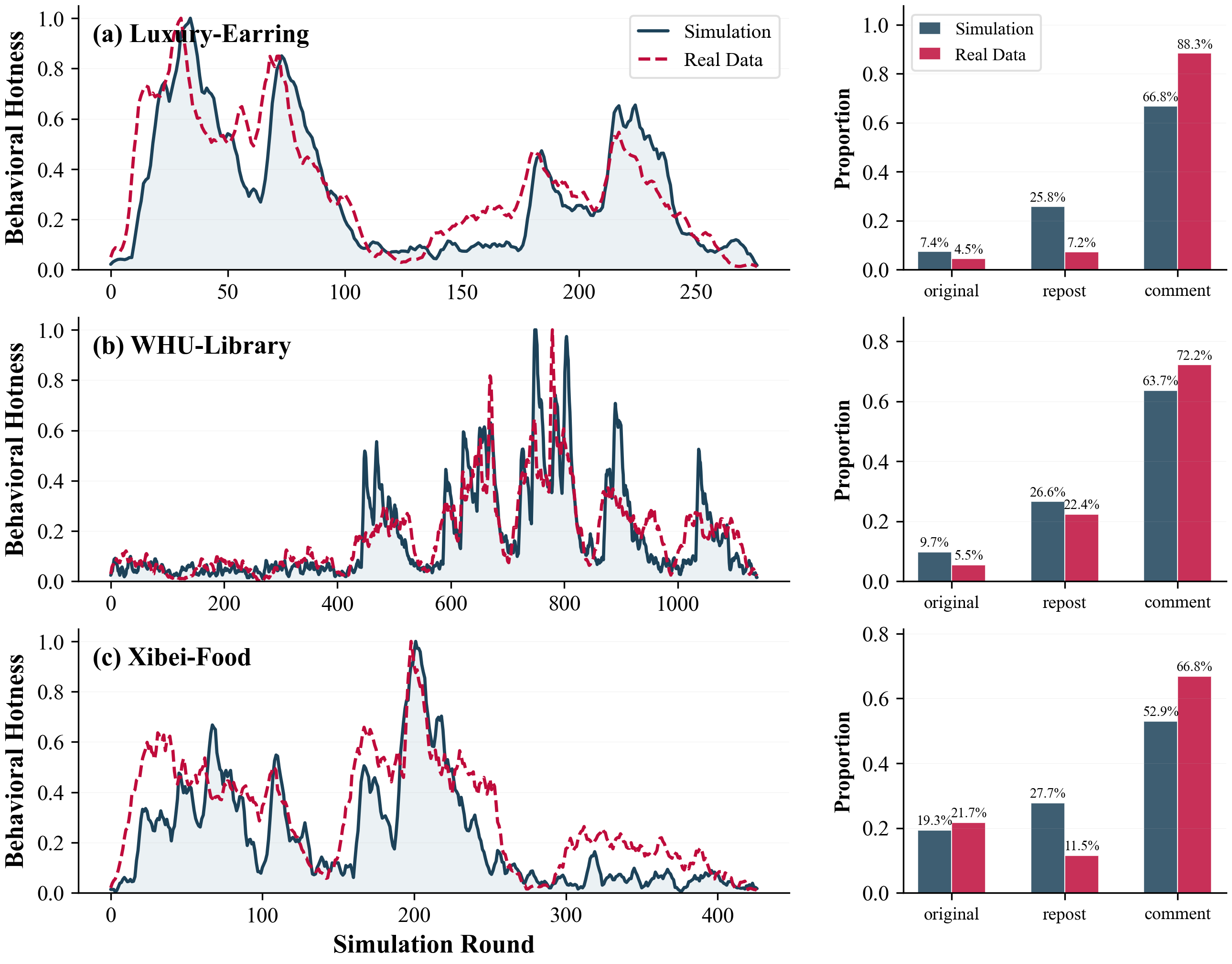
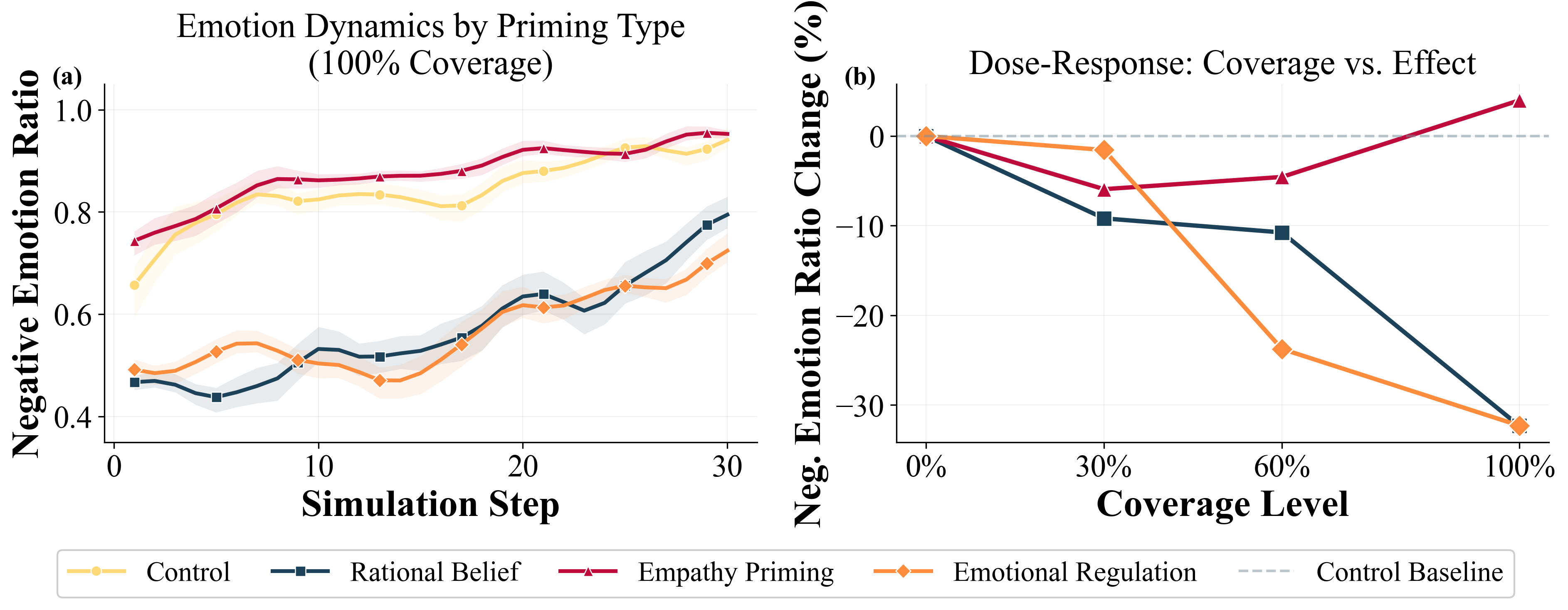
POSIM: A Multi-Agent Simulation Framework for Social Media Public Opinion Evolution And Governance
Embedding Large Language Models into a layered Social-BDI cognitive architecture to build agents with explicit cognitive states and traceable decision chains, driven by Hawkes self-exciting point processes for high-fidelity public opinion simulation.
"All models are wrong, but some are useful." — George E. P. Box
Python 3.8+
PyTorch 2.0+
OpenAI Compatible LLM
MIT License